Основные понятия MPI. Парадигма SPMD
If (myProc.eq.0) then
< делать что-то одно >
else if (myProc.eq.1) then
< делать что-то другое >
. . .
else
< делать что-то P-e >
endif
MINUIT как типичный объект для распараллеливания
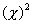 . Минимизируемая функция оформляется пользователем как
фортрановская подпрограмма FCN. MINUIT используется для решения широкого
круга задач: от математической обработки результатов физического
эксперимента до фундаментальных проблем теоретической физики.
Такая популярность этой программы и побуждает выбрать именно ее как
объект распараллеливания прежде других.
. Минимизируемая функция оформляется пользователем как
фортрановская подпрограмма FCN. MINUIT используется для решения широкого
круга задач: от математической обработки результатов физического
эксперимента до фундаментальных проблем теоретической физики.
Такая популярность этой программы и побуждает выбрать именно ее как
объект распараллеливания прежде других.
Подпрограмма SEEK
do 1 k=1,Nseek
do 2 i=1,N
2 x(i)=xbest(i)+0.5*(rndm(1)+rndm(2)-1)*werr(i)
-> if(Mod(k,Nproc).ne.MyProc) goto 1 !parallelization
y=FCN(x)
if(y.lt.ymin) then
do 3 i=1,N
3 xbest(i)=x(i)
ymin=y
endif
1 continue
-> call MN_Best(xbest,ymin)
if(Mod(k,Nproc).ne.MyProc) . . . (1)
реализует основную идею разделения работы между процессами:
- все работы каким-то способом пронумерованы;
- каждый процесс исполняет только работы, соответствующие его номеру;
- полученные результаты объединяются и становятся общим достоянием.
Подпрограмма MIGRAD
Do 1 i=1,N
-> if(Mod(i,Nproc).ne.MyProc) goto 1 !parallelization
x(i)=x(i)-step(i)
y1=FCN(x)
x(i)=x(i)+2*step(i)
y2=FCN(x)
grad(i)=(y2-y1)/2*step(i)
-> call MN_SendGrad(i)
1 continue
-> call MN_SendGrad(0)
Подпрограмма SIMPLEX
Do 1 i=1,N
-> if(Mod(i,Nproc).ne.MyProc) goto 1 ! parallelization
! определение i-й точки симплекса
-> call MN_SendPoint(i)
1 continue
-> call MN_SendPoint(0)
Типовые этапы работы над MINUIT
- Организация обрамления программы. Добавлены подпрограммы MN_Start и MN_Finish для захвата и освобождения MPI-ресурсов, каковыми являются временная группа процессов и вспомогательные типы данных. Временная группа процессов необходима, чтобы скрыть внутренние коммуникации MINUIT от использующей его прикладной программы, которая, в свою очередь, может быть распараллелена независимо!
- Проработка набора базовых коммуникационных операций, специфичных именно для MINUIT. Их получилось немного, всего 6. Это две только что упомянутые обрамляющие операции MN_Start и MN_Finish, три основные операции (MN_Best, MN_SendGrad, MN_SendPoint), используемые в центральной части программы, и одна вспомогательная операция MN_Bcast, о которой речь пойдет чуть ниже. Реализованы все они как отдельные подпрограммы, в основной же текст добавляются только вызовы этих подпрограмм. Именно это обеспечивает как локальность изменений авторского текста, так и возможность работы при любом числе процессов, в частности и при P=1. Здесь принципиальным должно являться требование, чтобы вызовы пакета MPI находились только внутри этих базовых операций, а не были "размазаны" по всей прикладной программе. Более того, все базовые операции используют внутренний, скрытый от пользователя, коммуникатор mn_comm, конструируемый в MN_Start, что является типичной техникой реализации библиотечных MPI-программ.
- Подготовка программ-заглушек пакета MPI - для обеспечения возможности эксплуатации этой версии MINUIT на тех машинах, где никакого MPI нет вообще. Базовые операции сконструированы таким образом, чтобы в качестве заглушек достаточно было иметь пустые подпрограммы, лишь бы загрузчик сумел реализовать все внешние ссылки. Наличие MPI-заглушек позволяет иметь единый текст как для последовательной, так и для распараллеленной программы, разница только в том, что распараллеленная программа использует настоящий MPI, а нераспараллеленная - его заглушки (stubs).
- Реорганизация операций ввода и вывода. Их в MINUIT много, программа
имеет весьма развитый интерфейс с пользователем. Печать, и вообще
весь вывод, естественно, должен выполнять только один из P процессов,
участвующих в совместной работе, и, очевидно, это должен быть процесс
0: ведь программа должна правильно работать при любом P, в частности
при P=1, а только нулевой процесс есть всегда, при любом составе
группы процессов, вовлеченных в решение задачи! Поэтому все операторы
вывода должны предваряться проверкой номера процесса:
If (MyProc.eq.0) Write(*,*) DataЧто же касается ввода, то тут чуть сложнее. Ясно, что файлы с входной информацией должны принадлежать кому-то одному, стало быть нулевому процессу. Прочитав из файла, он должен поделиться прочитанным со своими партнерами:If (MyProc.eq.0) read(1,*) (data(i),i=1,count) call MN_Bcast(data,count) !Propagate for all processesЭто типичная техника организации ввода начальных данных при распараллеливании программы. Добавляются две вещи: условный переход и MN_Bcast - последняя из шести базовых коммуникационных операций. MN_Bcast практически идентична MPI_Bcast, но маскирует от внешнего окружения как используемый коммуникатор mn_comm, так и номер координирующего процесса.
Некоторые результаты тестирования
50
--
FCN = > (x(i)-i)**2 ,
--
i=1
дающей минимум, равный 0 при x(i)=i, использовалась и тестовая
FCN, предложенная автором MINUIT.
| Variant | AsTime | Processes CPU-times | Total | FCN-calls | F/AT |
| 0 | 8.2 | 8.17 | 8.17 | 10069 | 1228 |
| 1 | 8.9 | 8.94 | 8.94 | 10069 | 1191 |
| 2 | 7.8 | 7.20+7.27 | 14.47 | 15942 | 2144 |
| 3 | 10.4 | 6.66+6.72+6.72 | 20.10 | 22013 | 2116 |
| 4 | 19.8 | 9.77+9.69+9.64+9.64 | 38.74 | 42490 | 2099 |
Приложение
common /mn_mpi/ mpi_size, ! number of processes = 1,2,...
2 mpi_rank, ! current process rank
! = 0,1,...,mpi_size-1
3 mpi_come, ! external communicator
! (usually MPI_COMM_WORLD)
4 mpi_comi, ! internal communicator
5 mpi_data, ! MPI kind of DataType (REAL or DOUBLE)
6 mpi_gtype,! Derived Type for Gradient (6 numbers)
7 mpi_stype,! Derived Type for Gradient
! (6*NPAR numbers)
8 mpi_npar, ! previous NPAR in mn_Send
9 mpi_time, ! used CPU-time
* LOUT ! flag for I/O permitted (mpi_rank=0)
real*8 mpi_time
logical LOUT
Function MultiMinuit(job) ! Parallel version of MINUIT via MPI
include 'minuit.cmn'
include 'mpif.h'
if(job.ne.0) call mn_start(MPI_COMM_WORLD)
! MPI init for global communicator
MultiMinuit=mpi_rank
if(job.eq.0) call mn_finish(MPI_COMM_WORLD)
! MPI finalization
return
end
subroutine mn_Start(comm) !MPI initialize for arbitrary communicator
include 'minuit.cmn'
include 'mpif.h'
integer comm
call MPI_INITIALIZED(Lout,ierr)
if(.not.Lout) call MPI_INIT(ierr) ! else init was done outside!
mpi_data=MPI_DOUBLE_PRECISION
if(Precision.eq.1) mpi_data=MPI_REAL
mpi_time=0
mpi_come=comm ! remember external communicator
call MPI_COMM_DUP(comm,mpi_comi,ierr) ! for internal exchanges
mpi_npar=1
call MPI_TYPE_VECTOR(6,1,MNI,mpi_data,mpi_gtype,ierr)
call MPI_TYPE_COMMIT(mpi_gtype,ierr)
! conctruct own types for mn_Send
call MPI_TYPE_VECTOR(6,mpi_npar,MNI,mpi_data,mpi_stype,ierr)
call MPI_TYPE_COMMIT(mpi_stype,ierr)
call MPI_COMM_SIZE(comm,mpi_size,ierr)
call MPI_COMM_RANK(comm,mpi_rank,ierr)
Lout=(mpi_rank.eq.0)
if (Lout) write(*,*) ' MPI-run using ',mpi_size,' processes.'
if (.not.Lout) isw(5)=-999! block printing !!!
if (.not.Lout) isw(6)=0 ! block interactive mode !!!
return
C
entry mn_Finish(comm) ! MPI finalization (comm does not matter!)
call MPI_COMM_FREE(mpi_comi,ierr)
call MPI_TYPE_FREE(mpi_gtype,ierr)
call MPI_TYPE_FREE(mpi_stype,ierr)
mpi_size=1
mpi_rank=0
mpi_npar=-1
return
end
subroutine mn_BCast(a,n) ! Breeding just read input data
include 'minuit.cmn'
include 'mpif.h'
if(mpi_size.eq.1) Return ! nothing to do
mt=mpi_data
if(n.lt.0) mt=MPI_CHARACTER
call MPI_BCast(a,iabs(n),mt,0,mpi_comi,ierr)
return
end
subroutine mn_SendGrad(i)
! Send i-th Gradient Info to Main Process ( i>0 )
! Join all Gradients and BCast them to all Processes ( i=0 )
! A Gradient Info is:
! MNDERI : GSTEP(i)+GRD(i)+G2(i)
! MNHES1 : GSTEP(i)+GRD(i)+DGRG(i)
! MNHESS : GSTEP(i)+GRD(i)+G2(i)+DIRIN(i)+YY(i)
! But we always will send all these 6 values.
! It's a self-constructed Type mpi_gtype
! of 6 Reals starting from GRD with strand=MNI
include 'minuit.cmn'
include 'mpif.h'
integer st(MPI_STATUS_SIZE)
if(mpi_size.eq.1) Return ! nothing to do
if(i.gt.0) then
if(mpi_rank.eq.0) return
call mpi_Send(grd(i),1,mpi_gtype,0,i,mpi_comi,ierr)
return
endif
if(mpi_rank.eq.0) then
do 1 j=1, NPAR ! receive from all others
if(Mod(j,mpi_size).eq.0) goto 1 ! these were calculated by us
call mpi_Probe(MPI_ANY_SOURCE,MPI_ANY_TAG,mpi_comi,st,ierr)
is=st(MPI_SOURCE)
it=st(MPI_TAG)
call mpi_Recv(grd(it),1,mpi_gtype,is,it,mpi_comi,st,ierr)
1 continue
endif
if(mpi_npar.ne.NPAR) then
call MPI_TYPE_FREE(mpi_stype,ierr)
!Reconstruct because NPAR maybe changed!
call MPI_TYPE_VECTOR(6,NPAR,MNI,mpi_data,mpi_stype,ierr)
call MPI_TYPE_COMMIT(mpi_stype,ierr)
mpi_npar=NPAR
endif
call mpi_BCast(grd(1),1,mpi_stype, 0,mpi_comi,ierr)
return
end
Function mn_SendPoint(i) ! called from MNSIMP
! Send (P(k,i),k=1,npar),Pbar(i),YY(i),?DirIn(i)
! to Main Process ( i>0 )
! Join all these arrays and BCast them to all Processes ( i=0 )
! Returns index of simplex vertex with minimal value of FCN
include 'minuit.cmn'
include 'mpif.h'
integer st(MPI_STATUS_SIZE)
index=NPAR+1
if(mpi_size.eq.1) goto 9 ! nothing to do
if(NPAR+2.gt.MAXINT) then
if(Lout) write(*,*) ' Too many params. SIMPLEX stopped.'
stop
endif
if(i.ne.0) then
p(NPAR+1,i)=pbar(i)
p(NPAR+2,i)=yy(i) ! dimension P(MNI,MNI+1)
if(mpi_rank.ne.0)
* call mpi_Send(P(1,i),NPAR+2,mpi_data,0,i,mpi_comi,ierr)
goto 9
endif
if(mpi_rank.eq.0) then ! main process
do j=1, NPAR ! receives from all except itself
if(Mod(j,mpi_size).ne.0) then
call mpi_Probe(MPI_ANY_SOURCE,MPI_ANY_TAG,mpi_comi,st,ierr)
k=st(MPI_SOURCE)
m=st(MPI_TAG)
call mpi_Recv(p(1,m),NPAR+2,mpi_data,k,m,mpi_comi,st,ierr)
endif
enddo
endif
call mpi_BCast(P,MNI*NPAR,mpi_data, 0,mpi_comi,ierr)
absmin=yy(index)
do j=1,NPAR
pbar(j) =p(NPAR+1,j)
yy(j) =p(NPAR+2,j)
if(absmin.lt.yy(j)) then
absmin=yy(j)
index=j
endif
enddo
9 continue
mn_SendPoint=index
return
end
subroutine mn_Best(n,a) ! called from MNSEEK
include 'minuit.cmn'
include 'mpif.h'
integer st(MPI_STATUS_SIZE)
dimension a(n),t(MNI) ! n=NPAR+1 a=args(NPAR)+func(1)
if(mpi_size.eq.1) Return ! nothing to do
if(mpi_rank.ne.0) then
call mpi_Send(a,n,mpi_data,0,mpi_rank,mpi_comi,ierr)
else
do i=2,mpi_size
call mpi_Recv(t,n,mpi_data,
& MPI_ANY_SOURCE,MPI_ANY_TAG,mpi_comi,st,ierr)
if(t(n).lt.a(n)) then
do j=1,n
a(j)=t(j)
enddo
endif
enddo
endif
call mpi_BCast(a,n,mpi_data,0,mpi_comi,ierr)
return
end
Литература
- http://parallel.ru
- http://www.openmp.org
- Воеводин В.В., Воеводин Вл.В. Параллельные вычисления. БХВ-Петербург, 2002.
- MPI: The complete Reference. MIT Press, Cambridge, Massachusetts, 1997.
- CERN Program Library Long Writeup D506. James. F. MINUIT. CERN, Geneva, Switzerland.
А.П.Сапожников